





loading...
Le prime iterazioni guardavano i replay dei giochi per apprendere le basi delle strategie "micro" (cioè unità di controllo efficaci) e "macro" (cioè economia di gioco e obiettivi a lungo termine). Con questa conoscenza è stato in grado di battere gli avversari di computer nel loro ambiente più difficile, il 95% delle volte. Ma come ogni professionista ti dirà, è un gioco da ragazzi. Quindi il vero lavoro è iniziato qui.
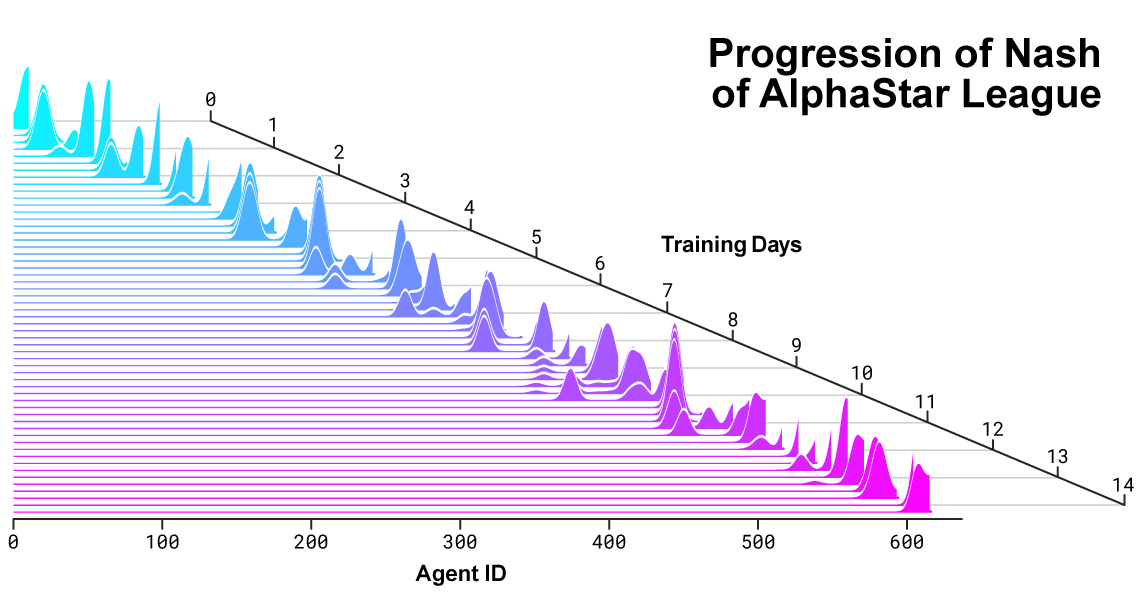
Poiché StarCraft è un gioco così complesso, sarebbe sciocco pensare che esista un'unica strategia ottimale che funzioni in tutte le situazioni. Quindi, una volta che l'agente di machine learning era essenzialmente suddiviso in centinaia di versioni di se stesso, ognuna di esse aveva un compito o una strategia leggermente diversa. Si potrebbe tentare di raggiungere la superiorità aerea a tutti i costi; un altro per focalizzarsi su una tecnica; un altro per provare vari tentativi di "formaggio" come i giunchi dei lavoratori e simili. Ad alcuni sono stati assegnati anche agenti forti come bersagli, preoccupandosi di nient'altro se non di aver superato una strategia già riuscita.
Questa famiglia di agenti ha combattuto e combattuto per centinaia di anni di tempo di gioco (intrapresi parallelamente, ovviamente). Nel corso del tempo i vari agenti hanno appreso (e ovviamente riportato) vari stratagemmi, da cose semplici come come spargere unità sotto un attacco area-di-effetto a reati complessi a più punte. Mettendoli tutti insieme ha prodotto l'agente AlphaStar estremamente robusto, con circa 200 anni di gameplay sotto la sua cintura.
La maggior parte dei professionisti di StarCraft II ha meno di 200, quindi è un vantaggio ingiusto. C'è anche il fatto che AlphaStar, nella sua incarnazione originale, ha comunque altri due importanti vantaggi.
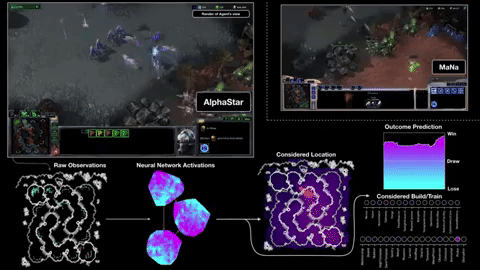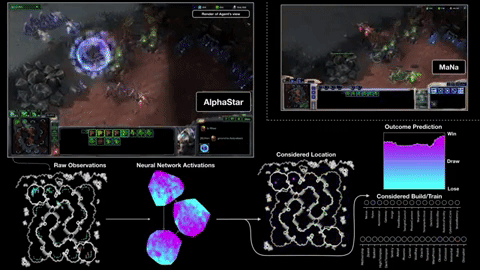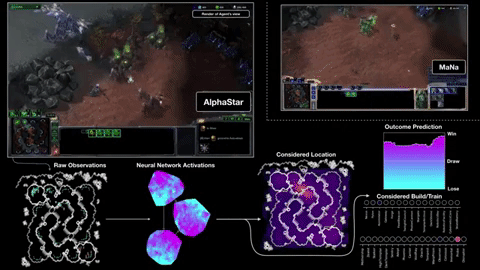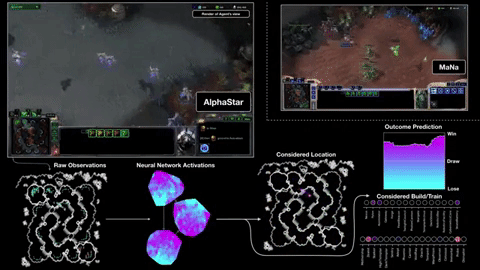
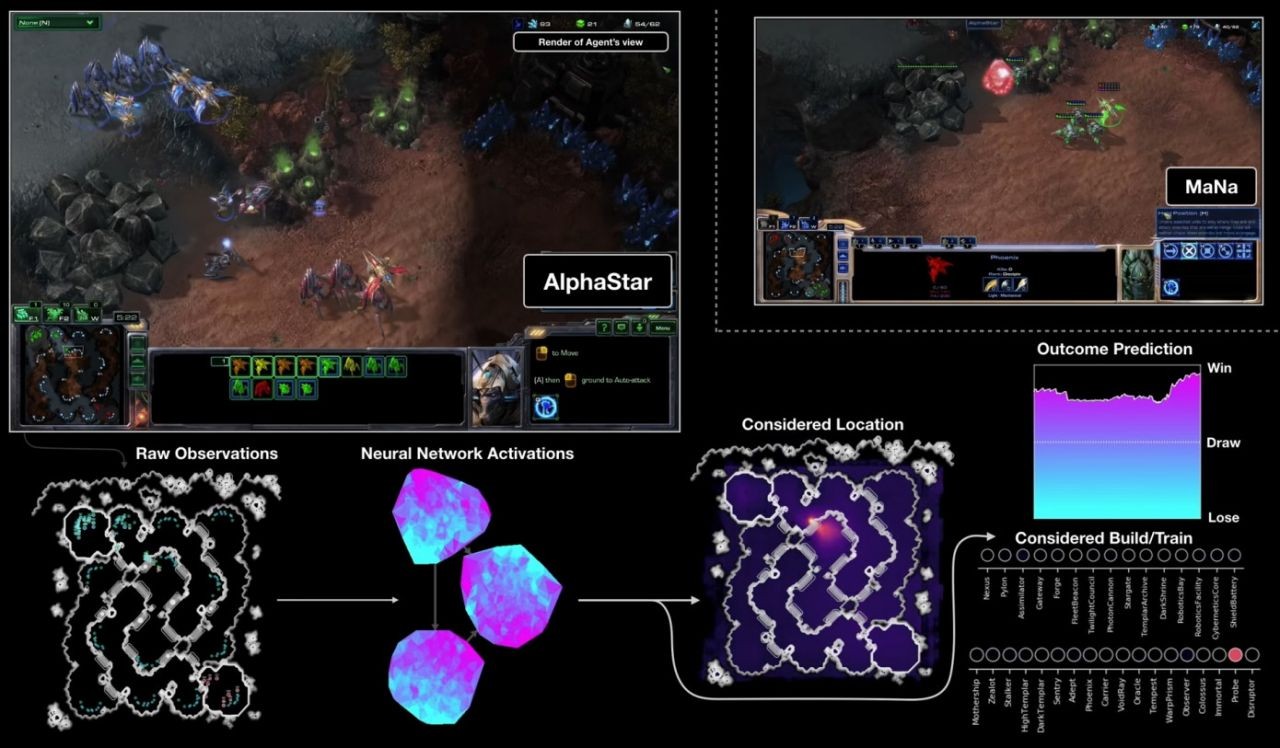
In primo luogo, ottiene le sue informazioni direttamente dal motore di gioco, piuttosto che dover osservare la schermata di gioco - quindi sa immediatamente che un'unità è ridotta a 20 HP senza dover fare clic su di essa. Secondo, può (anche se non sempre) eseguire molte più "azioni al minuto" di un umano, perché non è limitato da mani carnose e banchi di pulsanti. L'APM è solo una delle misure che determina il risultato di una partita, ma non può far male essere in grado di comandare un ragazzo venti volte in un secondo invece che in due o tre.
Vale la pena notare che le IA per il controllo micro esistono da anni, avendo dimostrato la loro abilità nell'originale StarCraft. È incredibilmente utile essere in grado di eliminare perfettamente le unità in uno scontro a fuoco in modo che nessuno subisca danni letali, o movimenti perfettamente temporali in modo che nessun attaccante sia ozioso, ma la verità è che una buona strategia batte buone tattiche praticamente ogni volta. Un buon giocatore può contrastare il micro perfetto di un'IA e rimuovere quel prezioso strumento dal gioco.
AlphaStar è stato abbinato a due giocatori professionisti, MaNa e TLO, del team Liquid altamente competitivo. Li ha battuti entrambi, e i professionisti sembravano eccitati piuttosto che depressi dalle capacità del sistema di apprendimento automatico. Ecco il gioco 2 contro MaNa:
Sono rimasto impressionato nel vedere AlphaStar tirare fuori mosse avanzate e strategie diverse in quasi tutti i giochi, usando uno stile di gioco molto umano che non mi sarei mai aspettato. Mi sono reso conto di quanto il mio gameplay si basi sulla necessità di forzare gli errori e di essere in grado di sfruttare le reazioni umane, quindi questo ha messo il gioco sotto una luce completamente nuova per me. Siamo tutti entusiasti di vedere cosa verrà dopo.
Nei commenti dopo la serie di giochi, MaNa ha riportato
E TLO, che in realtà è uno dei principali Zerg, ma ha giocato con Protoss per l'esperimento:
Sono rimasto sorpreso da quanto fosse forte l'agente. AlphaStar prende strategie ben note e le stravolge la testa. L'agente ha dimostrato strategie a cui non avevo pensato prima, il che significa che potrebbero ancora esserci nuovi modi di giocare che non abbiamo ancora completamente esplorato.
Puoi ottenere i replay delle partite qui.
AlphaStar è indiscutibilmente un giocatore forte, ma ci sono alcuni avvertimenti importanti qui. Innanzitutto, quando hanno svaligiato l'agente facendolo suonare come un essere umano, nel senso che doveva spostare la telecamera, poteva solo fare clic su unità visibili, avere un ritardo simile alla percezione umana, e così via, era molto meno forte e infatti è stato battuto da MaNa. Ma quella versione, che forse potrebbe diventare il punto di riferimento piuttosto che il suo cugino non legato, è ancora in fase di sviluppo, quindi per questo e per altri motivi non sarebbe mai stata così forte.
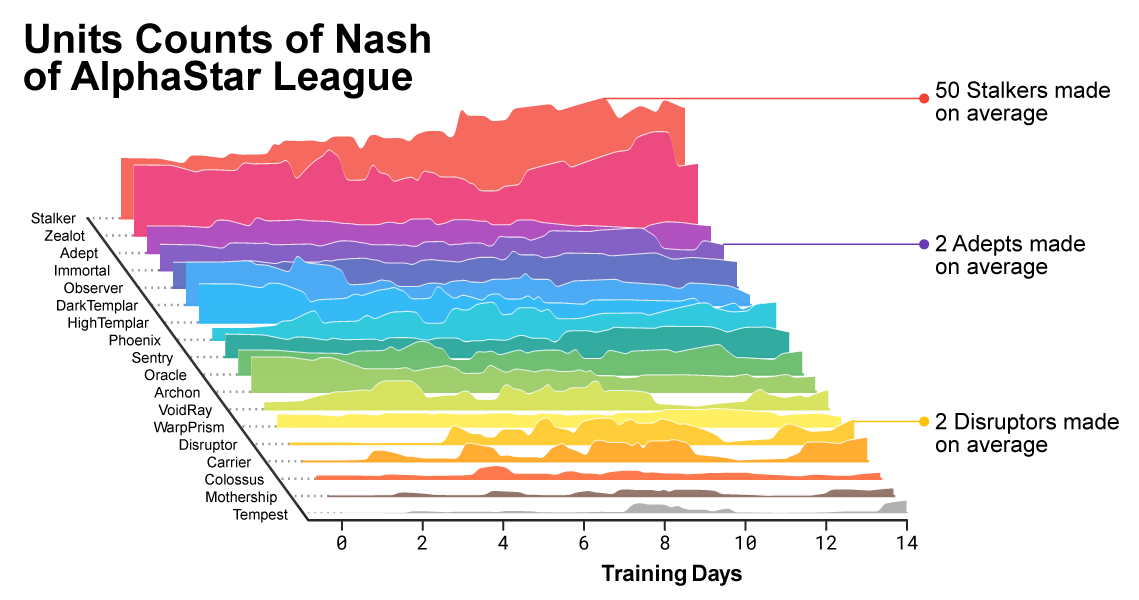
Soprattutto, AlphaStar è ancora uno specialista estremo. Gioca solo Protoss contro Protoss - probabilmente non ha idea di come sia un Zerg - con un solo avversario, su una singola mappa. Come può dirti chiunque abbia giocato al gioco, la mappa e le gare producono tutti i tipi di variazioni che complicano enormemente il gameplay e la strategia. In sostanza, AlphaStar sta giocando solo una piccola parte del gioco, anche se molti giocatori si sono specializzati in questo modo.
Detto questo, la base per progettare un agente di auto-formazione è la parte difficile: la formazione effettiva è una questione di tempo e potenza di calcolo. Se è 1v1v1 su Bloodbath, forse è il tempo di stalker / zelot, mentre se è 2v2 su una grande mappa con molta elevazione, vengono le unità aeree. (È ovvio che non sono in vetta alla mia SC2?)
Il progetto continua e AlphaStar diventerà più forte, naturalmente, ma il team di DeepMind pensa che alcune delle basi del sistema, ad esempio come visualizzare in modo efficiente il resto del gioco a seguito di ogni sua mossa, possano essere applicate in molte altre aree in cui le IA devono prendere decisioni più volte che riguardano una serie complessa e di risultati a lungo termine.
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.
By accepting you will be accessing a service provided by a third-party external to http://www.imperoweb.it/

Non è ammessa nessuna copia i contenuti sono protetti da diritti d'autore.